
Imagen de advanz101.com
En esta entrada hablare del concepto bussines intelligence (a
partir de ahora nos referiremos a ello como BI) dentro de las empresas.
Seguramente os estéis preguntando que tiene que ver la inteligencia empresarial
con el mundo de los datos, ya que, este blog gira entorno a eso, gestión de datos,
información, búsqueda y manipulación de los datos y la información. Pues tiene
mucho que ver, ya que, el concepto de BI se crea gracias a la necesidad en las
empresas de poder administrar, crear conocimiento y realizar estrategias a través
de los datos de dichas organizaciones (empresas). Dicho esto, entraremos en
materia.

Imagen de MEVESI.COM
¿Qué es BI?
BI es la habilidad o capacidad que dispone una empresa para
convertir la información (obtenida de los datos de la empresa) en conocimiento,
para después utilizarlo en nuestro beneficio. Es decir, con el conocimiento que
ha sido generado gracias a los datos empresariales, podremos tomar decisiones
con más seguridad y probabilidad de que la decisión tomada genere un caso de éxito.
En la siguiente imagen podemos contemplar que la relación que
guardan los datos con la información se denomina como BO (Busnisse operator,
que son una serie de componentes que explicaremos más adelante) y que sin el
BO, no podríamos obtener la información necesaria para convertirla
posteriormente en conocimiento.
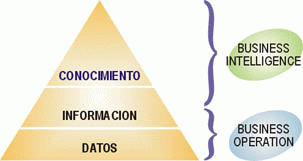
Imagen de sinnexusCOM
Bi se compone de varias herramientas que nos facilitan la extracción
de datos y su compresión.
¿Qué herramientas
pueden componer BI?
Como hemos mencionado BI se compone de varias herramientas.
Principalmente hay tres herramientas.
- Cuadro de mando. Es una herramienta de monitorización del rencimiento, ayuda a reducir la incertidumbre y facilitar la toma de decisiones. Por lo cual es una herramienta a la ayuda de toma de decisiones. Existen dos tipos de cuadros de mando:
o
Cuadro
de mando operativo (CMO) Herramienta
de control, está enfocada a recoger información de variables
operativas(pertenecientes a departamentos específicos). Un CMO debe estar
siempre ligado a un DSS para poder profundizar en los datos.
o
Cuadro
de mando integral (CMI) Es una
herramienta de control que ayuda a las organizaciones a expresar sus objetivos
e iniciativas necesarias a llevar a cabo para cumplir con las estrategias
fijadas. En otras palabras, es una herramienta que nos ayuda a fijar objetivos
en los diferentes departamentos de la organización y monitorizarlos. En dicho
cuadro de mando podemos observar 4 perspectivas genéricas(que no en todas las
organizaciones tienen que existir)
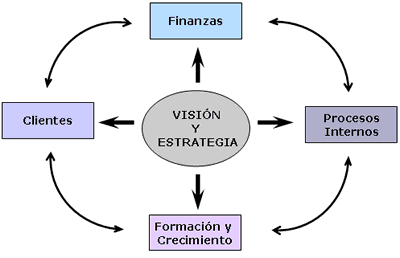
Imagen de sinnexusCOM
- Sistema de soporte a la decisión (DSS) Herramienta enfocada al análisis de datos en una organización. Nos permite resolver gran parte de las limitaciones de los programas de gestión de datos, ya que normalmente dichos programas suelen disponer de informes estáticos y generales. Las características principales de un DSS son:
o
Informes
dinámicos, flexibles e interactivos. Como hemos mencionado anteriormente, rompemos la limitación de tener
informes estáticos y generales.
o
No requiere
conocimientos técnicos. Un
usuario puede utilizar dicha herramienta para generar gráficos e informes de
manera fácil.
o
Rapidez
en tiempo de respuesta.
Gracias a que las bases de datos que usan están optimizadas para el análisis de
grandes volúmenes de información y datos.
o
Perfiles
de usuarios. Cada usuario
tiene su propio perfil, por lo cual, tendrá acceso a la información adecuada a
dicho perfil.
o
Historial.
Dispone de un historial accesible para ver los movimientos de cada periodo histórico
de la compañía.

Imagen de 4.bp.blogspot.COM
- Sistema de información para ejecutivos (EIS) Es una herramienta SW, basada en un Sistema de soporte a la decisión (DSS), con la peculiaridad de que está enfocada a que los gerentes de la organización tengan un acceso sencilla a la información. Lo que le proporciona es la posibilidad de analizar al detalle cada indicador del negocio. Y así, poder establecer estrategias necesarias a cada indicador.

Estas son las
principales herramientas que contiene un BI. Pero, por otro lado, los datos que
emplea BI para llevar a cabo su correcto funcionamiento son obtenidos de los
siguientes componentes:

- Datamart. Es una base de datos departamental, esto quiere
decir que la base de datos está especializada en el almacenamiento de datos de
un área específica. Este componente se caracteriza por disponer de una
estructura óptima de datos para analizar la información al detalle desde todas
las perspectivas que puedan afectar a los procesos de dicho departamento. Para
la creación de un datamart de área funcional, es preciso encontrar una
estructura óptima para el análisis de la información. Dependiendo
de los datos, requisitos y características específicas de cada departamento,
podremos decidir entre los siguientes tipos de datamart.
o
Datamart OLAP
Construido a partir de la agregación
de las dimensiones e indicadores necesarios según los requisitos de cada área.
o
Datamart OLTP
Introduciendo mejoras en su
rendimiento, aprovechando las características particulares de cada
departamento.
Las características que hay que tener en cuenta para reconocer si estamos
ante un buen datamart son:
o
Bajo
volumen de datos
o
Validación
directa de la información
o
Rapidez de
consulta
o
Facilidad
para guardar historiales.
o
Consultas
sencillas
- Datawarehouse. Datawarehouse o también conocido como almacén de datos, es una Base de datos corporativa, caracterizada por integrar y depurar la información de una o varias fuentes, para luego poder procesarla, permitiendo el análisis de dicha información desde distintas perspectivas y con gran velocidad de procesamiento. La instalación de un Datawarehouse es el primer paso, desde un punto de vista técnico, para implantar una solución completa y fiable de BI. Los Datawarehouse son caracterizados por ser:
o
Integrados. Las inconsistencias existentes deben ser
eliminadas.
o
Temáticos. Los datos son organizados por temas para
facilitar el acceso y el entendimiento por parte de los usuarios.
o
Históricos. Deben tener una correlación temporal.
o
No volátil. Los datos almacenados no pueden ser
modificados ni borrados.
o
Metadatos. Contiene datos sobre los datos. Es decir, esos
datos permiten saber la procedencia de la información, si están actualizados,
fiabilidad, etc. El objetivo de estos metadatos es:
>Soporte al usuario final. Dar ayuda al usuario para la construcción de
consultas, informes, análisis, etc.
>Soporte a responsables. Especificación de las interfaces para la realimentación
de los sistemas a través de los resultados obtenidos.
Con esta información
podemos decir que Los sistemas y componentes del BI se diferencian de los sistemas
operacionales, en que están optimizados para realizar consultas y divulgar los
datos. Con esto queremos decir que un datawarehouse, contiene los datos
desnormalizados para apoyar las consultar realizadas de alto rendimiento,
mientras que los sistemas operacionales , se suelen encontrar los datos
normalizados, para apoyar operaciones continuas , como son de inserción, modificación
y borrado. Por lo cual, los procesos de extracción, transformación y carga que
nutren los sistemas BI, Tienen que tomar los datos de uno o varios sistemas
operacionales normalizados a un único sistema desnormalizado, cuyos datos estén
completamente integrados en nuestro sistema.
Como resumen podemos
quedarnos con que una solución completa de BI nos permitirá:
- Observar Que está ocurriendo en la organización
- Comprender Por qué está ocurriendo esto en la organización
- Predecir teniendo cierta información ser capaces de saber que ocurrirá
- Colaborar Que debería hacer el equipo para mejorar la situación
- Decidir Que escoger en las diferentes situaciones
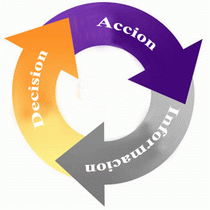
Es decir, tendremos
una serie de información, que nos servirá para decidir y tomar acciones, dichas
acciones nos darán más información para volver a decidir y volver a tomar más
acciones. En definitiva, tendremos un sistema de retroalimentación que podemos
observar en la image anterior.
Un saludo y unicamente se me ocurre una cosa que deciros por seguir este blog.
 |
Bibliografía
Wikipedia
Apuntes de clase
http://www.sinnexus.com/business_intelligence/























{kind=link}